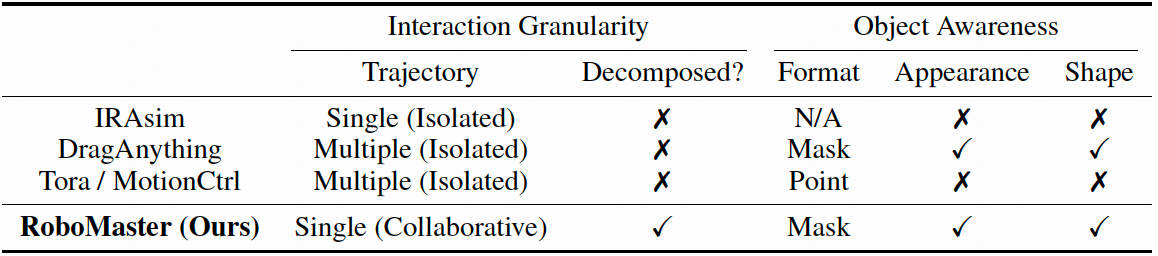
RoboMaster synthesizes realistic robotic manipulation video given an initial frame, a prompt, a user-defined object mask, and a collaborative trajectory describing the motion of both robotic arm and manipulated object in decomposed interaction phases. It supports diverse manipulation skills and can generalize to in-the-wild scenarios.
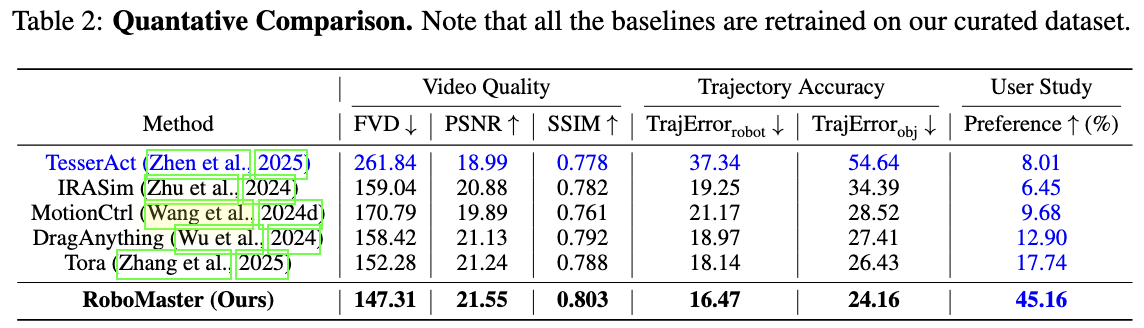
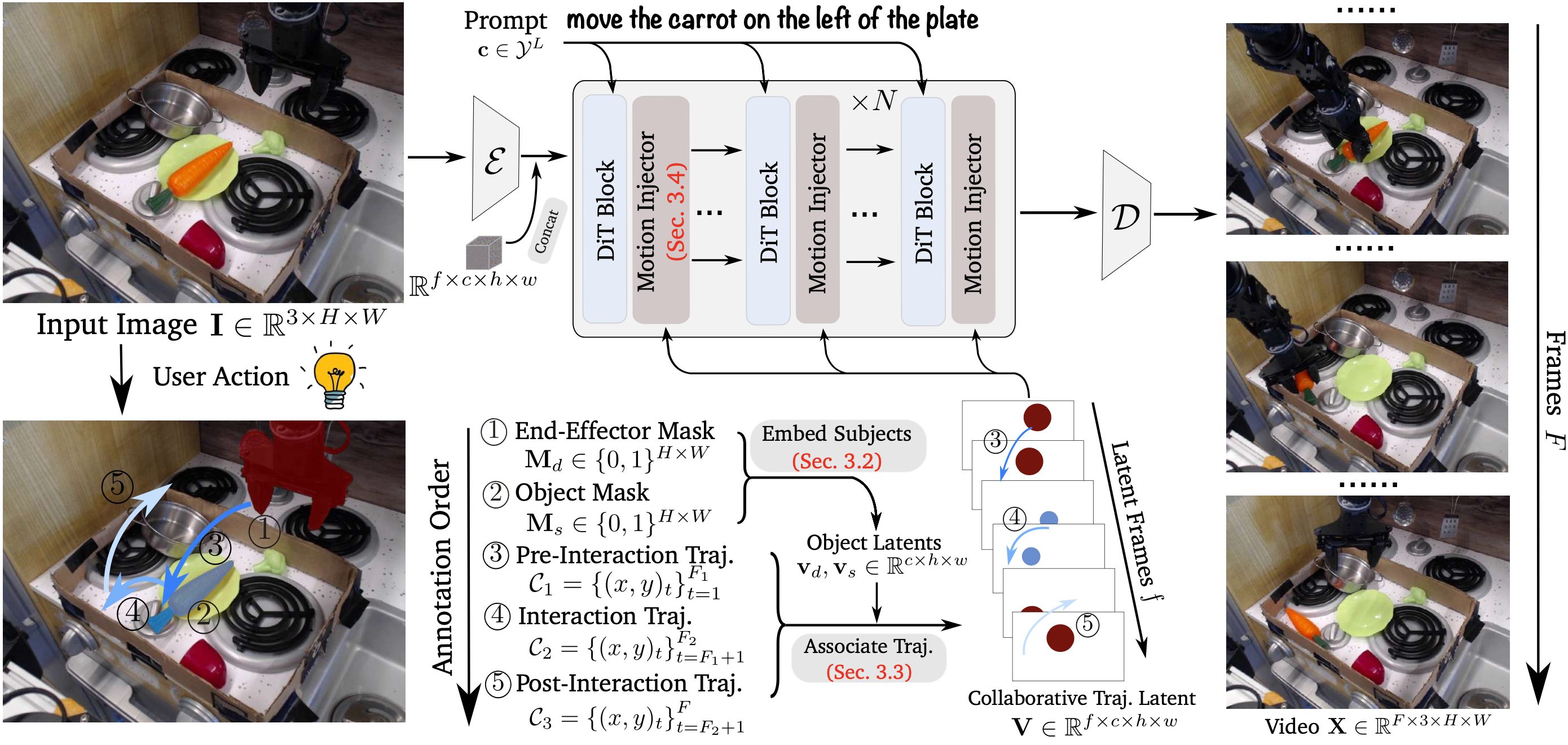
Unlike Tora that decomposes objects and uses separate trajectories to model the motion of robot arm and manipulated object, we decompose the interaction phase and unify their joint motions into a single collaborative trajectory with fine-grained object awareness. This integration alleviates the feature fusion issue in overlapping regions (see the missing apple in Tora), and improves visual quality.